About
LesionShiftAI is an end-to-end research benchmark I built to study how well skin lesion classification models generalize under dataset shift. The project focuses on binary benign vs malignant classification using dermoscopic images, with models trained and validated on ISIC 2019 and externally tested on HAM10000. The motivation was to go beyond internal validation accuracy and evaluate whether models that perform well on one dataset can still make reliable predictions when tested on images from a different source distribution.
The project compares multiple deep learning approaches for melanoma risk classification, including a baseline ResNet50 CNN, a five-fold ResNet50 ensemble, ViT B16, and a larger ViT L16 model. All models were trained through a shared pipeline that handled data loading, preprocessing, binary label mapping, training, validation, checkpointing, metric export, and external testing. Images were standardized to 224x224 pixels, with training augmentations such as flips and brightness or contrast jitter, while validation and testing used deterministic preprocessing to keep evaluation consistent.
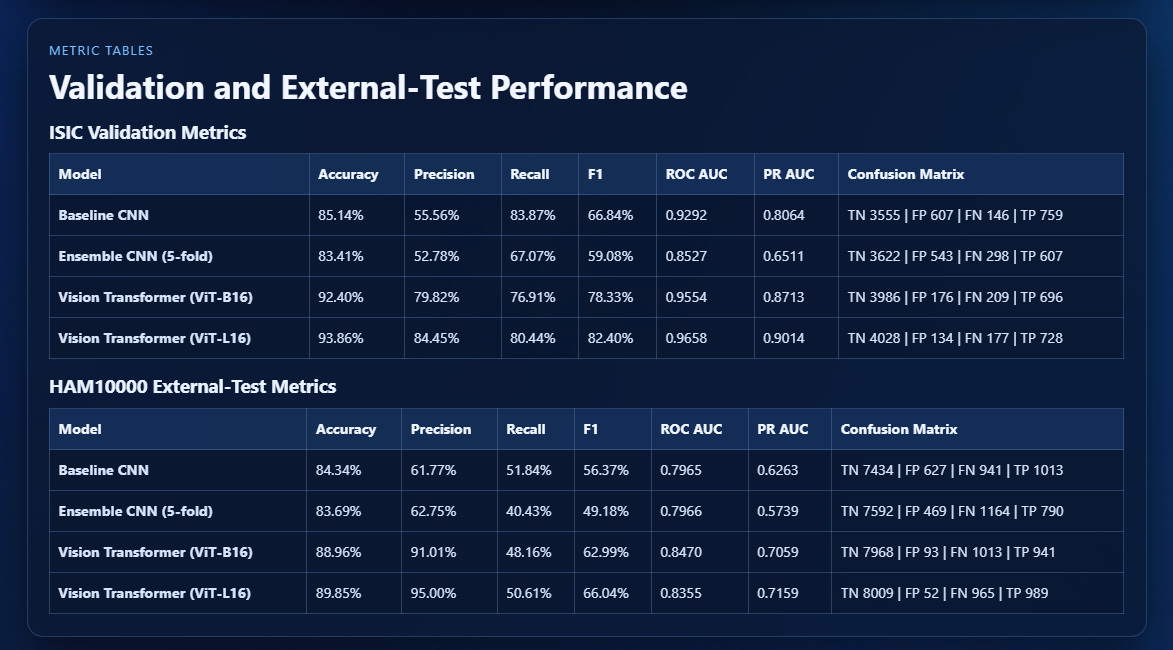
A central part of LesionShiftAI was evaluating model performance with clinically meaningful metrics rather than relying only on accuracy alone. Because malignant lesions are the high risk class, I tracked metrics such as recall, F1, ROC AUC, and PR AUC, with special attention to false negatives because they represent malignant lesions incorrectly classified as benign. The results showed that all models experienced some performance drop on HAM10000, confirming that dataset shift is a major challenge in medical image classification. However, the ViT L16 model achieved the strongest overall performance across most major validation and external testing metrics, suggesting that larger pretrained vision transformers may offer stronger generalization than the CNN based approaches tested.
From an engineering perspective, LesionShiftAI was structured as a reproducible machine learning framework rather than a single experiment. The repository includes configurable training scripts, model-specific pipelines, metric outputs, prediction exports, ROC and precision-recall curve generation, unit and integration tests, and SLURM launch scripts for running experiments on NAU's Monsoon HPC cluster. The project also supports artifact export for checkpoints, predictions, metrics, and generalization gap analysis, making it easier to compare models consistently and reproduce results across experiments.
The project also highlights important ethical limitations of applying AI to medical screening. LesionShiftAI is not a diagnostic tool, but a research benchmark intended to study generalization behavior across datasets. The strongest model still produced false negatives on external testing, which reinforces the need for careful threshold tuning, broader dataset representation, and clinical oversight before any model like this could be considered for real-world decision support.